I've been experimenting with ways to get Claude Code to conduct deeper, more structured research rather than just answering one-off questions. The result is the Claude Deep Research Model — a repo that provides a structured framework for running multi-step research workflows.
The motivation
LLMs are great at answering questions, but real research requires more than a single prompt-response cycle. You need to gather context, process information through different analytical lenses, iterate on findings, and produce organized outputs. I wanted a pattern that would let me set up research projects as repeatable workflows rather than ad-hoc chat sessions.
How the model works
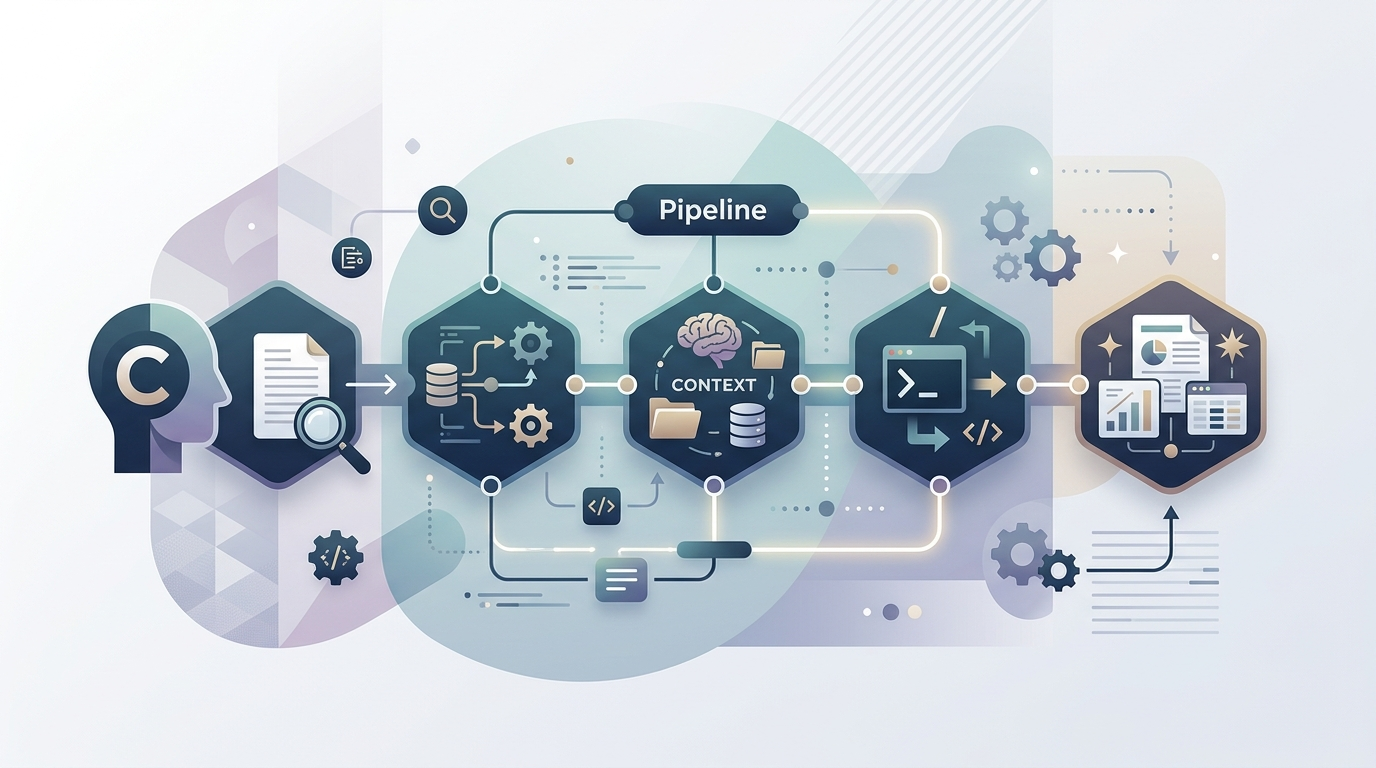
The model is organized around a model-base/ directory that contains everything Claude Code needs to run research workflows. There's a pipeline/ directory for processing configurations — these define the stages of a research workflow. A context/ directory holds background information and reference material. prompts/ contains system prompts and templates, while outputs/ collects the generated results. Custom slash commands tie everything together for Claude Code integration.
The key idea is that research isn't a single step — it's a pipeline. You feed in a topic or question, it gets processed through multiple stages (gathering sources, analyzing them, synthesizing findings, generating reports), and you get structured output at the end. The scratchpad directory provides a working area for experiments and drafts along the way.
Why this matters
The pattern shifts research from being a conversation to being a project. Version control means you can see how your understanding evolved. The pipeline structure means you can refine individual stages without starting over. And because it's a repo, you can fork it and adapt the pipeline to different research domains — market analysis, technical evaluation, literature review, whatever you need.
I also recorded a concept discussion about this as a podcast episode on Spotify if you prefer to hear the thinking behind the model rather than read about it. The repo is on GitHub and open source.